State Management in Dispatch Routing
While the optimization algorithm is the core of dispatch routing, what must be developed alongside it is persistent state management involving the database. In our pre-booking airport shuttle ridesharing service, routing is performed sequentially each time an order comes in, and there is a “routing state” that changes over time across all orders. Here we explain that state management along with the underlying architecture.
Service Architecture
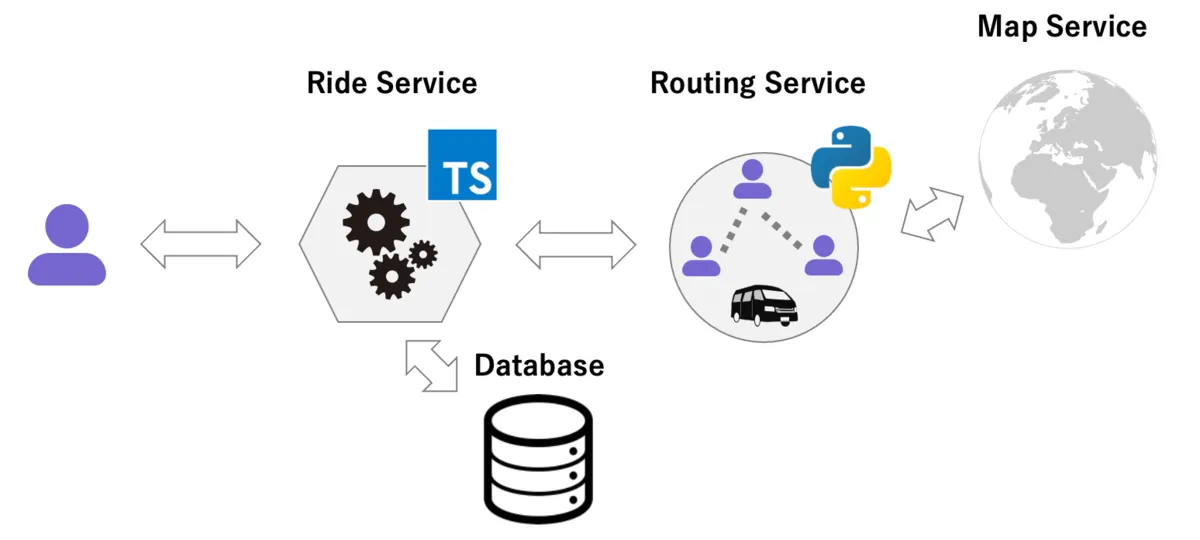
The dispatch routing system we have built at NearMe is split into two services.
The first is the routing service, which provides the optimization algorithm. It does not interact with the database directly; it is stateless, receiving input and returning output. However, it does communicate with a mapping service to retrieve travel times along the shortest path between points.
The second is the ride service. This service interacts with the database and manages all the various states related to rides. It receives operations from users, drivers, and operators. It then uses the routing service to compute the next “routing state” from the current one and updates the database.
The reasons for splitting the services are, first, that we wanted to use the best language for each. At NearMe we primarily write TypeScript, but the routing service uses Python for its mathematical optimization libraries. Second, we wanted to be able to scale the routing service independently on CPU-optimized machines. While the bottleneck in the ride service is the database, the bottleneck in the routing service is the CPU. Additionally, separating the stateless and stateful boundaries makes the system easier to reason about. As a result, each codebase has grown independently and the separation has improved overall clarity.
State Transitions
In dispatch routing, we decide which orders are matched with which other orders. For each trip, we also determine the boarding and alighting order for passengers and compute a route consisting of multiple waypoints. If a route becomes too long, the match is rejected. A match is also rejected if it would exceed the vehicle’s passenger capacity, or if it deviates too far from the user’s preferred departure or arrival time.
In general, this is a combinatorial optimization problem, and the computational complexity explodes as the number of elements increases. Therefore, before reducing it to a combinatorial optimization problem, we first narrow down to an appropriate number of orders. At the same time, we try to ensure that filtered-in and filtered-out orders do not match each other as much as possible. For example, in the airport shuttle ridesharing service, we first apply a coarse filter by time and space — using the date as the time dimension and the service area (such as “Haneda Airport Transfer” as described in Multi-tenancy in Our Dispatch Service) as the spatial dimension. This filtering is performed quickly using database indexes.
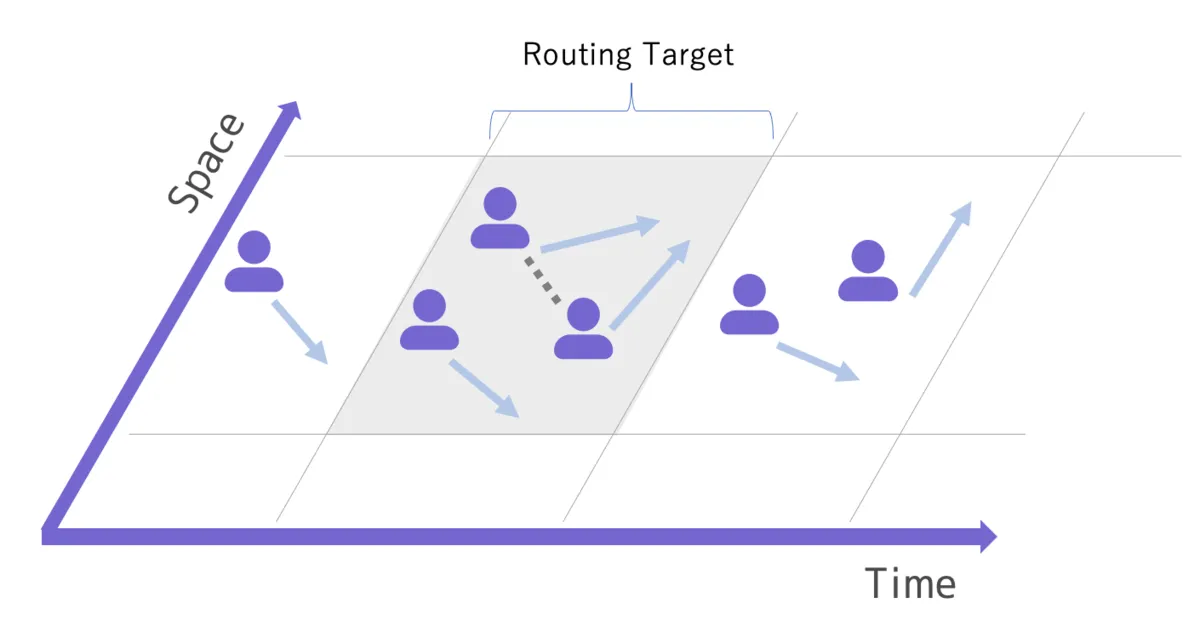
After the initial filtering, dispatch routing is run each time an order comes in or is cancelled. At this point, the previous routing result is saved and used as the basis for computing the next routing using the optimization algorithm. Within the algorithm, the problem is further narrowed to orders “close” to the incoming or outgoing order, and the combinatorial optimization problem is solved in a hill-climbing fashion.
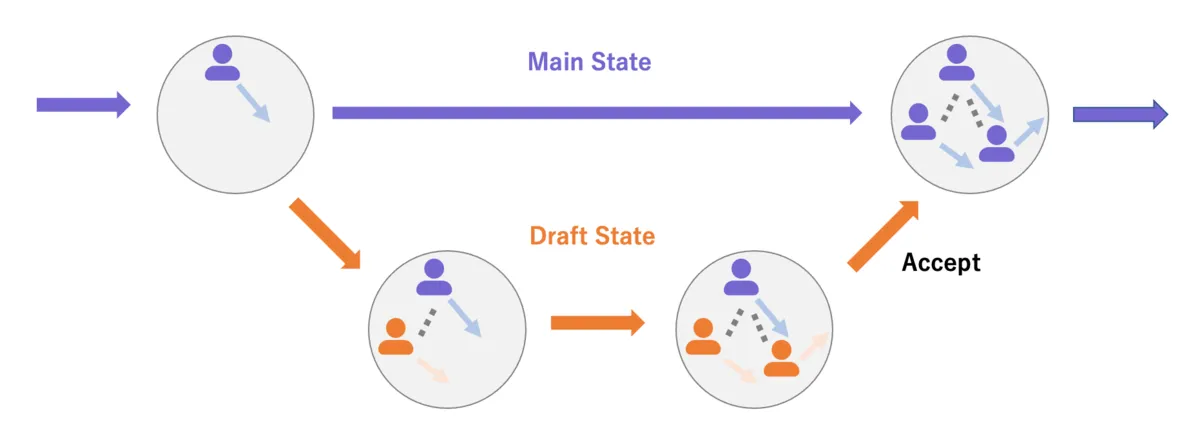
When the dispatch approval status of each order is added to the mix, a new type of state must be considered. When an order comes in, the operations manager or driver is notified and determines whether dispatch is possible based on the route, vehicle availability, and other factors. For advance reservations in particular, this determination may take some time. During that interval, additional orders may come in or others may be cancelled. At this point, the “routing state” branches: one branch consists only of approved orders (“canonical state”), and the other includes both approved and pending orders (“draft state”). Users and drivers see the canonical state, while approvers see the draft state. The draft state derives from the canonical state and, after a series of steps, is merged back into it. When all orders associated with a given trip are approved, those orders are merged. Conversely, without this branching, no additional orders could be accepted while dispatch approval is pending, resulting in missed opportunities.
At each routing step, orders may be grouped together or separated in pursuit of a better solution. Even orders that were previously grouped may be separated if a better grouping with other orders is found. When considering the scope of changes, any order within the filtered set — not just the newly added order and its matches — can potentially change. When saving the routing result, we extract only the changed portions and apply a differential update. This wide scope of impact is also relevant to the locking mechanism described later. However, since cross-trip order reassignment can complicate operations, we have made it possible to restrict reassignments to pending (unconfirmed) orders only.
As a side note, there is also a batch-based approach that performs routing all at once at a scheduled time, rather than this sequential approach. Batch processing is simpler from a state management perspective. While the sequential approach does yield practically acceptable solutions, a batch approach that spends more time solving the problem globally may find better solutions. The downside is that dispatch approval decisions are deferred until the batch runs, so users must wait longer to find out whether their ride is confirmed. Handling orders that come in after a batch has run also requires a separate mechanism.
Locking
One critical concern in database operations is locking (mutual exclusion) to maintain data consistency. Locking becomes necessary when asynchronous requests — such as new orders, cancellations, and dispatch approvals — operate on the shared resource that is the “routing state.”
As a simple example, consider what happens if a user cancels an order at the same time the operations manager approves it. Normally, order approval should be rejected by a validation rule that prevents it if the order has already been cancelled. Without locking, when a cancellation and an approval are requested simultaneously, both may first read the order in the same state — in this case, a pending (unapproved) state. The cancellation request is then processed and the order state is updated to cancelled. When the approval request is subsequently processed, it still holds a reference to the order in its original pending state, so the validation does not catch the cancellation, and the order is incorrectly set to approved. The user thinks they cancelled, but the order ends up approved and processed. Locking prevents this kind of inconsistency.
There are two approaches to locking: pessimistic locking and optimistic locking. Pessimistic locking designates the shared resource as the lock target and prevents other requests from reading it. In the example above, when cancellation and approval are requested simultaneously, one is processed first and updates the state before the other proceeds. If the cancellation is processed first, the approval request reads the cancelled state and is correctly rejected by the validation. Optimistic locking, on the other hand, speculatively executes each request and discards the operation if the state has changed since it was last read when attempting to write.
The choice between pessimistic and optimistic locking is nuanced, but in general we consider pessimistic locking to be simpler and easier to work with. Optimistic locking requires adding a version field to each record to detect changes (though a timestamp can sometimes be used instead), as well as implementing recovery logic for when updates fail due to conflicts. In particular, automated recovery requires a queue system, which itself demands careful attention. Optimistic locking is appropriate when conflicts are rare and automated recovery is unnecessary, when you absolutely need higher throughput (though speculative execution increases system load), or when pessimistic locking is not available due to database limitations. Implementing optimistic locking later as an optimization is also a valid option.
With that background established: the “routing state” that changes over time across all orders also requires locking each time an order comes in or is cancelled. As mentioned, once past the coarse filtering stage, it is generally impossible to know which orders will change without actually running the algorithm, so in the pessimistic locking case, the lock must be applied at the filtering stage. In practice, we maintain a dedicated lock table, creating records keyed by date × area and acquiring locks on them. At this point, the throughput ceiling is determined by the processing speed of the optimization algorithm. Currently this is not a problem, but if we ever hit the limit, we would need to apply finer-grained time or area partitioning to reduce lock granularity.
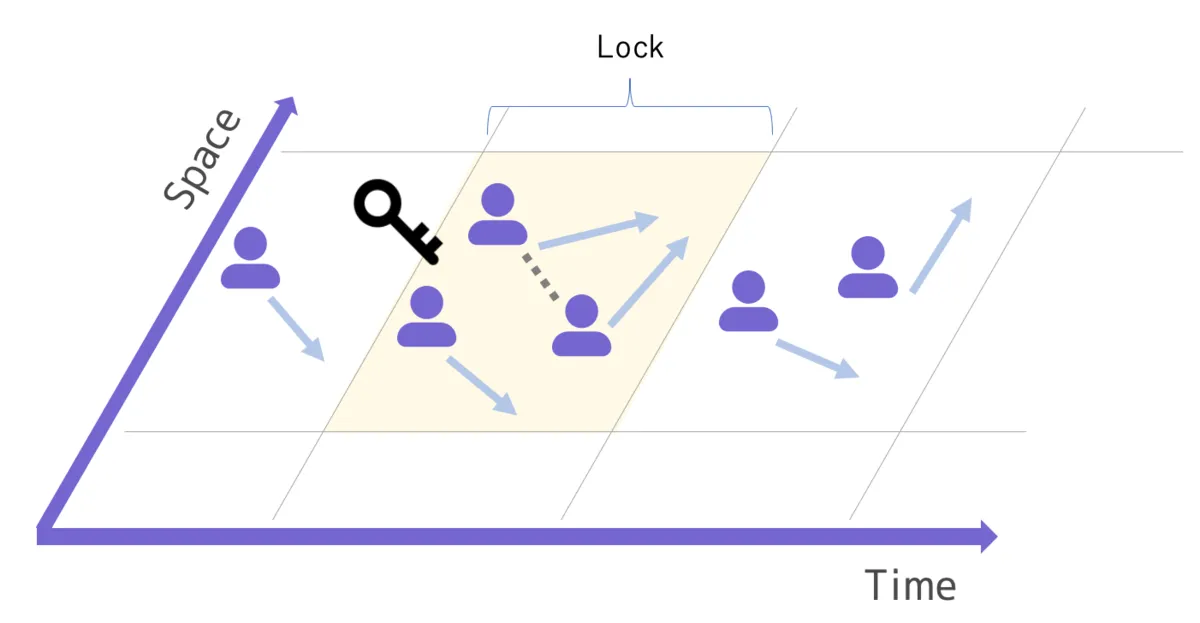
It is also possible to apply optimistic locking to the “routing state” using per-order version management. However, this introduces a new concern. For example, when a new order and a cancellation are requested simultaneously, the new order might fail to match a trip that it could have matched had the cancellation been processed first — because it is computing the next routing state based on a version that does not yet reflect the cancellation. In contrast, with pessimistic locking over the entire affected order set described earlier: if processed in the order cancel → new order, the new order naturally matches the trip from which the cancellation freed capacity. If processed as new order → cancel, the new order initially does not match that trip, but when the cancellation is subsequently processed, nearby orders are rearranged, giving the previously unmatched new order a chance to match. From a global optimization perspective, pessimistic locking has a clear advantage here.
Closing Thoughts
We have described the state management behind the dispatch routing system built at NearMe. It required careful consideration of many aspects: service decomposition, data filtering, sequential optimization, draft state branching, cross-trip order reassignment, and locking. We have also shown how each of these factors relates to routing performance.
Finally, NearMe is hiring engineers! If you want to dive deeper into dispatch routing optimization, or if you think you can optimize it even further, we’d love to hear from you.
Author: Kenji Hosoda